TADA! Tuning Audio Diffusion Models through Activation Steering
Abstract
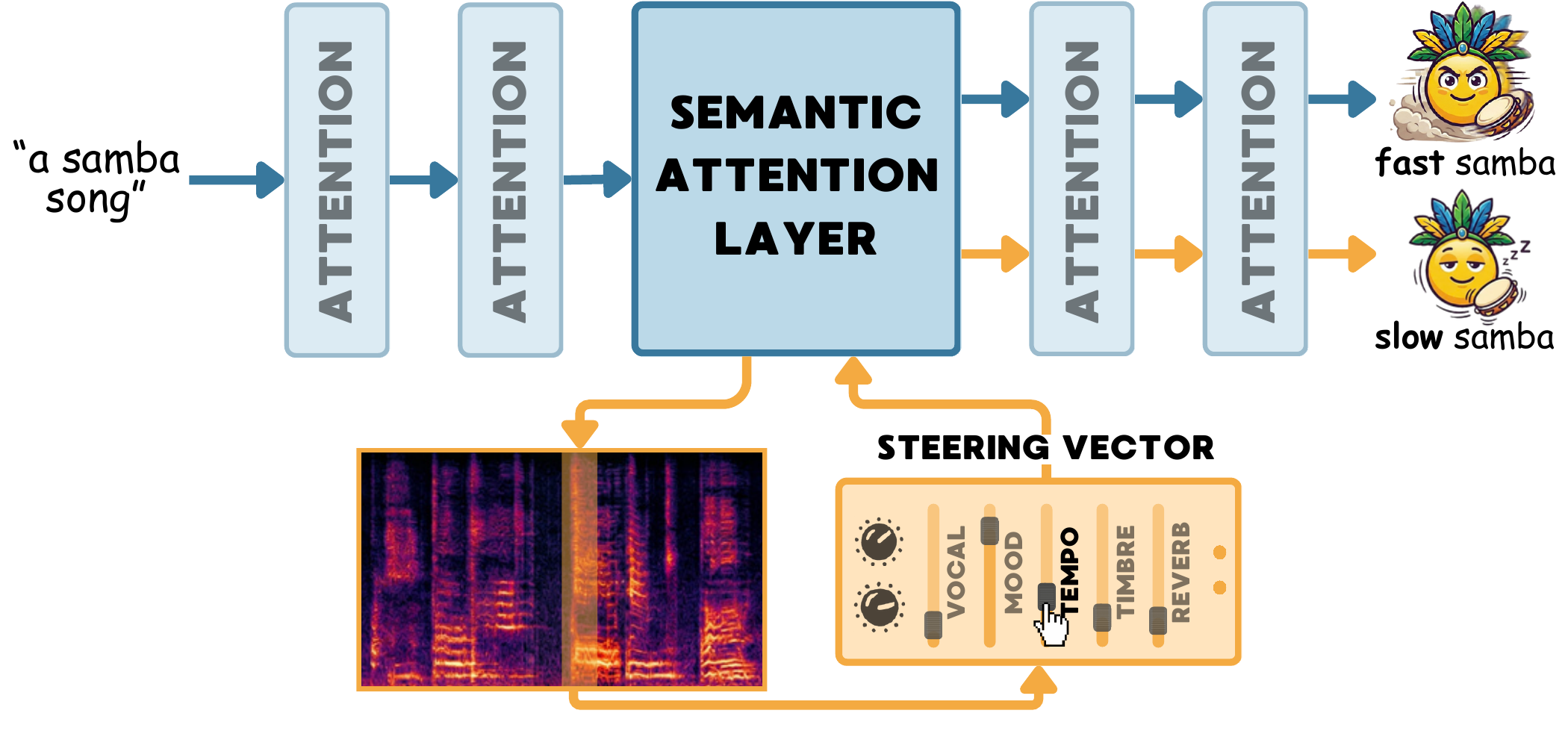
Text-to-audio diffusion models have shown impressive capabilities in generating realistic audio from text descriptions, but they often lack fine-grained control over specific audio attributes. We present TADA (Tuning Audio Diffusion with Activation steering), a lightweight method for steering the generation process of pre-trained audio diffusion models by manipulating their internal activations. Our approach identifies concept-specific steering vectors from a small set of contrastive audio pairs and uses them to guide the diffusion process toward desired audio characteristics, such as the presence of specific instruments, vocal qualities, tempo, or mood, without retraining the model. We demonstrate that TADA enables continuous, fine-grained control over multiple audio attributes simultaneously, generalizes across diverse text prompts, and can be combined with existing text-to-audio models as a plug-and-play module. Extensive experiments show that our method achieves effective attribute control while preserving overall audio quality and text alignment.
Audio Examples
Use the slider to select a steering strength (α). For each prompt, compare the four approaches side by side.